本文是GPU并行程序优化系列的第一部分,介绍GPU编程原则、优化层次,及优化的基本流程,建立起优化概念。建议有一定的CUDA编程基础,再来阅读文本。不多说什么,Let’s go ahead!
今天我们谈谈GPU程序优化。我们想要使用并行平台(GPU)的原因就是为了更快地解决问题,或高效地解决更大、更多的问题。用GPU获得加速是一件很酷的事儿,但也意味着要做额外的努力来最大化速度。往往花费在优化部分的时间远远大于编程本身的时间。
Catalog
GPU编程原则及优化层次
使用GPU编程的原则(直观概念):
- 最大化算术强度 maximum arithmetic intensity
- 减少在内存操作上的时间消耗 decrease time spent on memory operations
- 合并全局内存访问 coalesce global memory accesses
- 避免线程发散 avoid thread divergence
GPU优化的层次:
- 选择好算法 Picking good algorithm
- 有效率的编写规则 Basic principles for efficiency
- 体系结构优化 Arch-specific detailed optimization
- 指令集的位操作微观优化 μ-optimization at instruction level
举几个例子,使用复杂度为O(nlogn)的mergesort,而不是O(n2)的insertion sort,属于第一层次优化;编写cache-aware的代码,属于第二层次;利用好vector registers,属于第三层次优化。
值得注意的是,在CPU中,这类是否运用体系结构优化可以产生很大的不同,例如,如果忽略了现代处理中存在的SSE或AVX寄存器,那只能得到CPU每个核上四分之一或八分之一的能力,而在GPU上,通过大部分经验,这类优化获得的加速通常较小。
GPU编程优化流程
GPU程序优化是一种系统优化过程——APOD!
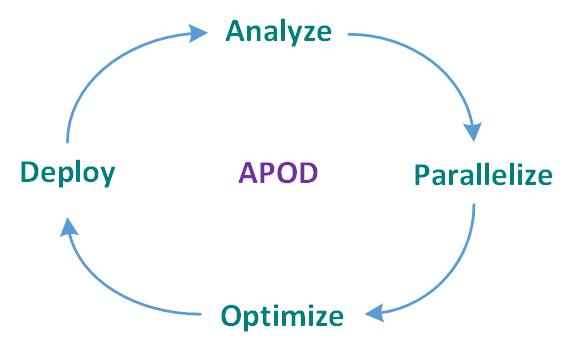
- A – analyze
- profile whole application, where can it benefit? By how much?
- 分析整体,弄清两个问题:
- 明白程序时间主要花在哪儿——程序员直觉 + 数据测试,gprof,vtune,verysleepy都是有用的profiler。
- 明白什么地方可以受益于并行化,并计算预期效果。
- P – parallelize
- pick an approach, and pick an algorithm (important)
- 当找到可以并行化的部分程序,有不同方法可以实现。比如有GPU并行库、Directives (OpenMP, OpenACC),或者写一个并行程序。
- 对于自己写并行程序,选择合理的算法非常重要,正确的算法会带来巨大运行效率。
- O – optimize
- profile – driven optimization (measure)
- 优化代码的过程将与优化过程来回循环。一定要多测量,以此为基础再去修改并行算法。
- D – deploy
- don’t optimize in a vaccum
- 实际运行中挖掘可以进一步优化的内容。
APOD构成一个循环,不要绕过任意一个步骤。现实中,很容易把时间大量用在P和O步骤中,其实更好地思考想实现什么,或者将优化程序实际运行一下看看效果以得到进一步的启发,这才是最重要的。