本文是GPU并行程序优化系列的第四部分,探究系统级相关的优化技巧。请参见“GPU程序优化”系列之前的文章。建议有一定的CUDA编程基础,再来阅读文本。
Catalog
Host(CPU)-Device(GPU)的交互
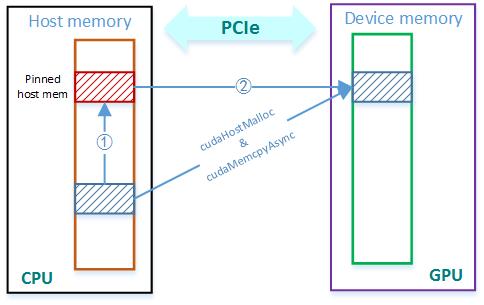
固定的host memory CPU与GPU通过PCIe通信,PCIe可以传输被页面锁定 (pinned) 或固定的内存,为此留出一块特殊的固定host内存。因此如果host上有一块内存想复制到GPU,得先将其复制到这块固定区域,之后再通过PCIe传输至GPU。这个额外的复制增加了内存传输的总时间。
有一种方法是,使用cudaHostMalloc()先分配固定host内存,使host上的内存准备好直接复制。传输时使用cudaMemcpyAsync(),使CPU在内存传输时能够保持工作。这又会使host和GPU之间的交互更快。
流 Stream
流是一系列将在GPU上按照顺序执行的操作,为了优化起见,可以把不同的任务分成不同流执行。
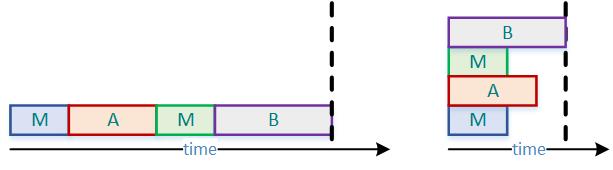
下列代码,每一步都按照顺序串行执行。
cudaMemcpyAsync();
A<<<...>>>(...);
cudaMemcpyAsync();
B<<<...>>>(...);
略加修改后,将其放置不同流中,使得多个操作可以同时进行,从而加快了速度。
cudaMemcpyAsync(..., s1);
A<<<...>>>(..., s2);
cudaMemcpyAsync(..., s3);
B<<<...>>>(..., s4);
Cuda流对象的类型是cudaStream_t。
cudaStream_t s1; // define stream
cudaStreamCreate(&s1); // create stream
cudaStreamDestroy(s1); // delete stream
GPU优化总结
总的来说,优化可分以下几方面,它们并不分立:
- APOD
- 提升内存带宽,多测试
- 保证足够的occupancy
- 对全局内存合并存取
- 最小化内存任务间的平均延迟
- 最小化分支发散
- 注意这是针对一个warp而言的,在不同warp中的分支发散无额外代价
- 避免过多的分支(if else, switch case)
- 避免线程工作量不平衡(loop)
- 快速的数学近似算法
- 解决运算性能受限
- 异步拷贝、流
- 重叠运算,解决host-device内存传输时间受限